Code Archaeology

Abstract
Software Engineers have to spend a considerable amount of time doing work that is not directly related to writing code. Much of this work falls into a category described here as “Code Archeology“, where the reasons, rationale, structure, and bugs of software must be clearly understood before improvements can be made. This work, which often requires deducing the reasons for historical decisions based on sparse evidence found via code artifacts. Because there is no visible and easily understood output to this work, it is often poorly understood and underappreciated by those outside of engineering departments. This article describes a case-study to illustrate what “code archeology” looks like in practice, in order to increase the understanding of this work for those who are only tangentially involved in software engineering.
Introduction
Sometimes an engineer will be working on a very difficult problem all day long and not have a single line of code to show for their efforts. It can be a pretty dissatisfying experience, and it can become down-right miserable if there is pressure from management and accusations of being lazy or not doing work. Such pressure is extremely counter-productive and not practiced in healthy software companies.
In unhealthy software companies, there can exist a managerial view, that believes that the only things engineers do is code, and that everything else is a distraction. This causes engineers to react by skipping the work it takes to understand a problem, and rush to implement whatever they currently understand. The ultimate result is buggy software that fails to meet customer expectations, cost overruns, and a complete destruction of any visibility into how long a project will take to finish.

Now, to say the opposite, that writing code has no value would also be absurd, because without code, you don’t have a project at all. Being able to code quickly and effectively is very important to the success of a project.
At some point or another, systems can end up in a state where they no longer satisfy customer demands, and there is very little documentation or institutional understanding of how the system works. When such situations arise, the work undertaken by an experienced engineer to uncover the purpose, structure, and nature of a system in order to change it is very similar to the work of an archeologist attempting to understand what an ancient society looked like only from the artifacts left behind in the form of pottery, ruins, or metal tools. Every engineer that ends up performing such a role quickly ends up coining a term similar to software archeology.
An Ounce of Prevention is a Pound of Cure

One of the biggest differences between healthy and unhealthy software organizations isn’t necessarily how fast the engineers write code. There are certainly differences in the speed between engineers, and some companies do a better job at attracting that talent. However, just hiring faster coders is not what leads to powerful successful companies like Google dominating markets.
At an organizational level, from department to department, or company to company, one of the most important differentiating factors in terms of overall speed, on the time-scale of months and years, is the rate of writing code that ALSO adds value to the product.
As a simple example, let us suppose we have several bugs in a software project that are preventing the release of features.
In addition to writing code that changes the software, there are often several other costs associated with getting that change into customer hands and determining if the bug has been fixed or if the feature meets customer expectations. Some of those costs include:
- Understanding the feature or bug.
- Writing the code for the feature or to fix the bug.
- Writing tests for the code that confirm the code meets the understanding of the problem.
- Fixing the code of older parts of the project whose assumptions conflict with the understanding of the problem.
- Deploying the code into a staging environment, where thorough testing assures that the new code does not introduce any conflicts with new/old versions of other deployed projects. For example, a fix to a back-end API may break certain versions of the Mobile App.
- Deploying the changes into a production environment, e.g. release into the Google Play or Apple Store can take days.
- Reacting to newly introduced bugs and misalignment between the feature and customer expectations.
There are many ways in which these costs can become multiplied as software is being developed. For example:
- If a bug is missed in the staging environment, then steps 2, 3, 4, 5, 6, and 7 need to be repeated.
- If a feature is not well understood, you have to do steps 1-7, realize the implementation is wrong, and then repeat steps 1-7 again.
- If a feature or bug is rushed without understanding multiple times, then steps 1-7 are repeated multiple times.

Even small mistakes can lead to costly deployments and delays waiting for customer feedback. This is especially true when developing Mobile Apps.
The time actually writing the code can be one of the fastest and least costly part of these cycles.
Properly understanding a problem, and solving it correctly the first time, reduces the total engineering effort from 10x to 100x.
Quickly deciding to build an elaborate bridge at the wrong location, going back to correct the location, and then rebuilding/moving that bridge to a new location is not efficient by any stretch of the imagination.
Example Pitfalls Associated with Poor Planning
Actually finding all the dependencies of a software change can be much more difficult than one might imagine. In this example, suppose we have a data entity known as a “Thing” in our system. The “Thing” has two properties, an “id” which is not being changed, and an “extension” whose value was originally an integer, but is being changed to a “string” to allow better a wider range of values that better integrates with different vendors.
In this scenario, an engineer that hastily looks at the code, finds all the visible dependencies, and gets the code to compile and tests to pass will update the components in green. In pink we see a few examples of a number of other problems that may not be recognized until much later, and result in costly efforts to uncover. If one is lucky, there will be customers screaming about broken features, and if one is unlucky, new security holes can be silently introduced, or systems that are used to detect intrusion may cease to function.
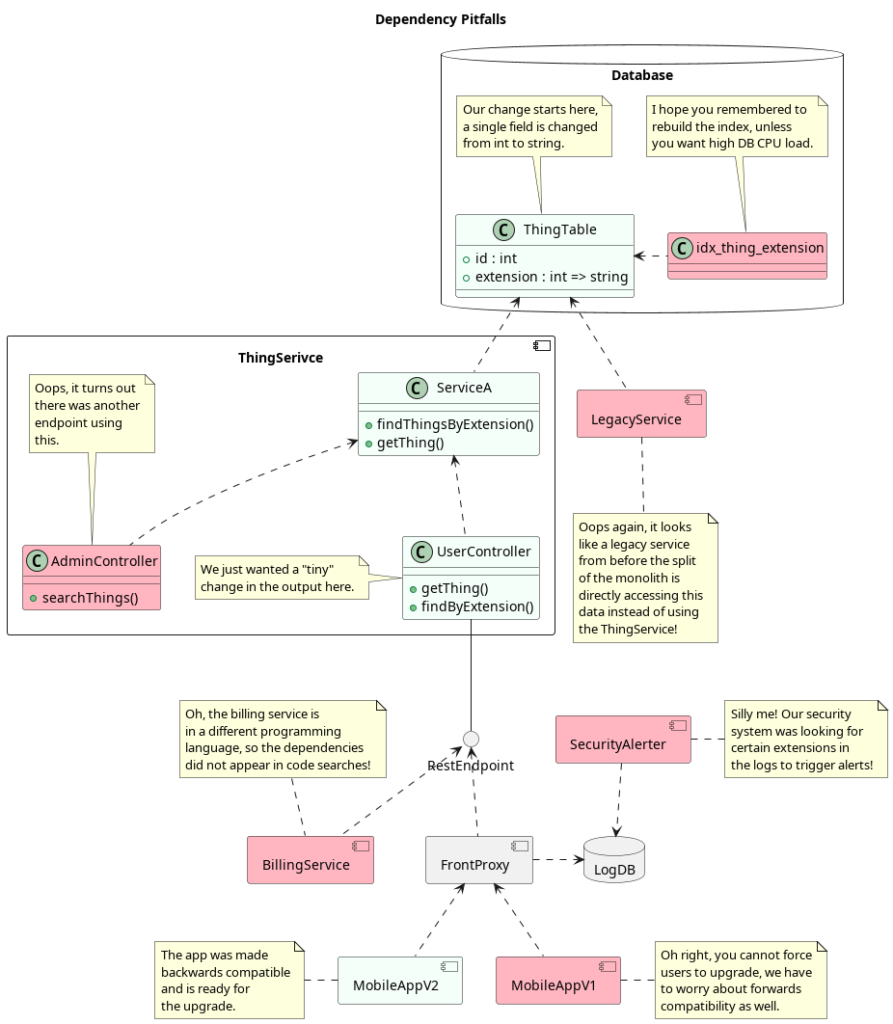
Our engineer was told how extremely time-sensitive the release of this feature is, how much customers depend on it, and how their own evaluation will be influenced by how quickly they get this work done. The engineer, in a state of high-alert and panic, took care of the obvious happy-path, quickly delivered a change.
The engineer updates the database to change the “extension” field from integer to string, updates the “ThingService” to use this new data format, updates the REST interface to include this new data, and even goes the extra mile and works over the weekend to dig into the Mobile App code and change that project as well to use the new data format. After all, he was told that every second counts, and he didn’t want any time to go to waste.
This made the managers happy, they check this feature off as done, and are already planning the next sprint, deciding what new features should be worked on next.
Then the emergencies begin.
- Even though the new version of the Mobile App works with the new data format, the old version does not, and the customer support calls begin to pour in. The customer service agents are overwhelmed, and the management instructs to help the customers upgrade their mobile app as a way of resolving this. It’s a lot of manual effort and results in a lot of exhausted customer support agents, but it gets done.
- Suddenly new errors show up and people are complaining that the service is unresponsive and not working. This results in a scramble from the DevOps team who discovers that the database is nearing 100% CPU and becoming unresponsive. Not knowing what the problem is, they immediately upgrade the size of the database in order to have more CPU. Unknown to them, the old database index on the “extension” field no longer exists, and each query is now doing a full table scan, dramatically increasing its CPU costs. This problem can keep revisiting the company each time the CPU gets to 100% again, and a deep dive into inefficient queries would have to be undertaken, with the investigators starting with next to no context about what to search for.
- Different customers start calling about errors in their billing, which depended on a completely different BillingService. As it turns out, the BillingService is not written in the same programming language as the ThingService, it merely calls the REST API, thus a simple code search did not uncover that this change would cause an error. The engineers are called in for the BillingService, who suddenly see an error in retrieving Things from the ThingService. They start to claim that the ThingService is malfunctioning, and that changes should be rolled back, but if they do that, then the new version of the Mobile App, which people are upgrading to, will break! This causes a lot of fighting between the engineers of the ThingService, BillingService, and the Mobile App.
- Customer Support, which was relying on internal endpoints only accessible in the company VPN suddenly finds that they are unable to investigate problems in Things for customers. This is because the Admin interface is now broken, because it was assuming that the “extension” field would be an integer, not a string! A new thread of complications that will agitate a lot of people.
- Legacy Customers using an ancient version of the system now also start breaking! Although the ThingService has been updated, it wasn’t the only user of the raw database data. As it turns out, the ThingService has been migrated out of an older monolithic system, which is now in legacy support mode, however, they still both share the same database! It is likely that there are no engineers who actually work on the Legacy system, and only few who even remember how it works. Our hapless engineer is called in after a long week and weekend of work to dive into this system he has never seen before in his life, find the error, and fix it.
- Six months later, it turns out that several accounts had been hacked and were transferring money to a fraudulent account, identified by its extension. It may be that a SecurityAlterter system existed that was monitoring accounts and looking for erratic and unusual behavior, and disabling access to extensions with this odd behavior. However, because the extension now has a different format, it was no longer able to function, resulting in a silent failure. No customers complained either, because they don’t use the company’s internal security systems. Can you guess how long it would take the SecurityAlerter engineers to figure out what went wrong?

Unfortunately, this circus of failures is a common situation in many inefficient companies, especially those that view engineering as a cost rather than an asset. The constant push to “motivate” engineers to work faster not only results in excess unpaid work hours, lower code quality, poor documentation, burnout, and higher churn, but it also results in slower overall development, because significantly more time is spent trying to investigate and fix bugs rather than actually working on new system improvements.
Situations like this are illustrative where doing a bit of code archeology up front ends up saving a lot of time in the long-run.
What Triggers the Need to do Code Archeology?
The time and effort it takes to do code archeology can be considerable, thus it should only be done for larger problems where existing processes have no clear answer. This typically occurs for systems that are either completely new, are poorly documented, and for which institutional memory has faded.

A few common triggers for beginning significant code archeology include:
- Data Format Changes: These cases come up when it is determined that a new feature requires additional data to be added, or for an existing data format to be modified.
- Software Library Upgrades: Whether a software framework has not been upgraded in a while, and it is desired to avoid security vulnerabilities, or a software dependency is being replaced with another in order to gain access to new features, the impact of such changes can quickly grow.
- Performance Improvements: It often occurs that performance problems stem from poor system architecture or software design, which results in too much data or computation being required on a single computer.
- Adding Assumption-Breaking Features: In order to be specific enough to be written into computer software, many assumptions must be made about the nature of a problem being solved. These assumptions are made to simplify the code being written, but when they are broken, it can result in a large number of changes to a system, because these a large amount of code depends on those very assumptions. In addition to a software system making assumptions, there can also be assumptions made by libraries and frameworks that a software system depends on.
What is Code Archeology?
It is clear that building software correctly the first time, as opposed to going through the entire software development lifecycle multiple times, can save tremendous amounts of time. If getting a complex change kicked off, defined, coded, tested, and released can take months, then does it make sense to “save time” by eliminating the day or two it takes to research and understand the problem? This faulty belief in “saving time” by eliminating “process” and “waterfall” is what leads many large software organizations with hundreds of people to release features more slowly than much smaller and less well funded companies.
Assuming your company wishes to be efficient, rather than throwing time and money down the toilet, it’s worth investing a little bit of time into researching and understanding a problem before beginning the software development.
When doing this research, what are the kinds of problems that one needs to be aware of and seek to avoid? Much of this work is akin to an archeologist doing an excavation of a dig site, having to look carefully at existing work and artifacts to understand what exists, and what could be damaged by new construction.
Code Archeology always begins with a change that must be made to a software system. Much of the work that has to be performed is done so that that change can be made correctly, and that it will not result in other software system failures while these changes are being deployed.
In a nutshell, code archeology is simply careful planning that takes existing systems into account.
It may include one or more of the following activities:
- Discovering the Real System Requirements: It is not uncommon to walk into a system that has been via a “move fast and break things” attitude, and things are now utterly broken beyond any quick fix and nobody has a clue what to do. In such cases, code may need to be eliminated, systems broken up and scaled, or anything else. Without knowing the goals of a system, it’s impossible to make any trade-offs or even know what optimization work is now “good enough”. There many places to dig when searching for the original goals of a system:
- Software Designs / System Architecture: If you are very lucky, a system will already have documentation that indicates why a system was built the way it was, the needs it was trying to solve, and it is quick to determine what has changed since this time, and how the system needs to be changed. However, most systems are completely undocumented.
- System Metrics: System metrics, such as the request rates, CPU utilization, memory usage, database I/O Operations per Second, and more are a great source of information to understand which parts of a system are failing to scale with increasing system load.
- Tickets / Stories: Very rarely, a Ticket or Story will be created in a system like Jira where the rationale behind a system is outlined. However, this form of documentation is almost always incomplete, difficult to find, and littered with ad-hoc modifications and internal contradictions. If the quality of Stories is poor and inaccurate, then it is best to not rely on them too much.
- Code and Comments: The code of a system is accurate in the sense in that it actually exists and accurately describes what the system currently does. It does not, however, describe the intent of a system. Some organizations misinterpret the phase “self documenting code” and believe that code should have no comments at all, which means that the intent of a system is left entirely undocumented. The code describes what exactly is present right now, bugs, misinterpretations, assumptions, and all.
- Industry Research: Often, the software being built is not entirely unique, and has goals and assumptions in common with other organizations. For example, all banks within a country are following similar anti-money-laundering, accounting, and other laws. Thus, information from these other companies or gained by reading common sources (such as banking laws or credit-card network manuals) can determine which assumptions in a malfunctioning system are invalid. This can give one the confidence needed to make repairs and changes without the fear of “throwing out the baby with the bath water”.
- User Research: Such documentation may be quite old, but there was likely some information presented to users that was used in the original sales, marketing, or investor slide deck that documented what the purpose of a system was. This can help uncover assumptions that later proved to be untrue, and explain why the system is structured as it is. Discovering features that were abandoned or fell out of use can be a good way to discover what code can be eliminated, which reduces the amount of code that must be reorganized.

- Determining System Architecture: Whether it is written down or not, a de-facto system architecture exists which describes the different software components, their interfaces, any any relevant algorithms. In the best case, they may simply involve the retrieval of existing documentation, but it is common for documentation to not exist or be out of date. Where documentation is lacking, it should be created to prevent others from having to do the same work in the future.
With a system architecture in hand, forming a checklist of services to inspect in response to a change becomes significantly easier.

- Determining Code Dependencies: Frequently there is no documentation or information about how functions or data are used outside of the code itself. In order to determine how much code could be impacted by a change, it often requires building call-stacks in reverse order. That is, starting from the data or function to be modified, find all the callers of that data or function. Add the calling function to the call-stack. If there are multiple callers, the create multiple call-stacks, with each of them copying the currently accumulating call stack.
If a call-stack reaches a function that acts as a receiver of an HTTP request, Kafka message, or any other external interface, then the call-stack should resume using the software project(s) that called the HTTP endpoint, sent the Kafka message, etc. The System Architecture is extremely useful to know what projects should be investigated.

- Identify Relevant Metrics: While producing call-stacks to determine code dependencies, take note of log statements and metrics that can be used as a proxy for usage of the system. These metrics and log statements can be used later on to determine whether an HTTP endpoint or Kafka message listener is being used at all. Code that is definitively not being used can be deleted. The fastest way to migrate code is to delete it. These metrics are also instrumental when determining if a step in a rollout plan has been successfully completed.
- Identifying Performance Constraints: While producing call-stacks to determine code dependencies, it can be very helpful to take notes about which operations are done sequentially vs. in parallel, which operations incur a network call, which operations incur a database call, etc. These notes are very helpful in identifying potential performance bottlenecks, and in formulating improvements. E.g. if the same data is requested 4 times from the DB in the call-stack, then introduce a caching layer, or request the data only once and pass it along as a function argument deeper in the call-stack.
- Create a Rollout Plan: Any change to a system cannot be simultaneously deployed to all software components in a system and servers instantaneously. Servers take time to redeploy, and during that time, different versions of different software will be operational. A rollout plan consists of an ordered list of changes to be deployed to software systems, such that minimal downtime is incurred in the system. If an error is encountered, the most recent step can be paused or rolled back before continuing.
For example, suppose a Mobile App calls a back-end service in order to obtain data that it displays to the user, and it is desired to add a new item of data to that list. If the Mobile App were to be deployed before the back-end is updated to produce the data, then the Mobile App will not be able to properly display the data (because it is not there). It would make more sense to upgrade the back-end service first to provide the new data, and then deploy the change in the Mobile App to read that data (assuming no errors are caused when the back-end adds additional data).

Output of Software Archeology
One isn’t going to get out of a problem the same way you got into it. People heaping changes after changes in a completely unstructured and undocumented manner led to a state of affairs where the system complexity became too large to fit into human memory, which led to a lack of understanding of the system itself. Thus, when doing work to understand a system, it’s very important to write down your finding in a structured way, allowing you to take a birds-eye-view of the system and see a clear path towards improvement.
The output of all this work is usually a thorough written plan that guides a complex series of changes to a system over many months in such a way that engineering teams are continuously productive and that there is no system downtime as each change is applied.
The format of such a plan is the subject of another article, but in organizations that I’ve led, they are typically called “Software Engineering Initiatives” and they are typically composed of the following sections:
- Abstract: Summarize the problem and the changes to be made, to give a better idea to reviewers if they should spend their time reading it.
- Background: Describe the system and the problem factually as they are, without polluting the situation with assumptions about how the problem should be solved. This should include a description of the current system, clarification of terminology, a description of problems the current system is facing, and any relevant metrics and evidence.
- Requirements: In an implementation-free manner, the problems described in the background should be condensed into a list of demands that any solution must satisfy. See Characteristics of Good Requirements.
- Analysis: At a high level, here is where any mathematical or architectural analysis should be done. For example, projections of future load or calculations of hardware limits based on evidence gathered from stress tests. A comparison and assessment of technologies that can be used can be done here as well.
- Method: The purpose of the method is to concretely pick a set of solutions to the problems, not to provide a list of choices with no decision. Whether this involves creating new software servers, altering the interfaces of existing services, replacing algorithms, changing database structures, etc., the desired new state of the system should be described here.
- Implementation: In this section, the work to be done should be broken down into specific changes for each software component involved. Along each major change to a software component, an approximation of how much time and effort will be needed to make such changes should be made. This helps other parts of the business understand the scope of the work.
- Rollout Plan: The changes to software components listed under “Implementation” should be ordered in such a way, so that backwards compatibility and continual system operation is maintained. This certainly does not mean that all work must be done serially, but rather that the order of release of these changes should be ordered.
- Acknowledgements/References: Give credit to those who helped, it’s just good manners.
Conclusion
Significant changes to a system require a completely understanding of all the software components that work together and how they depend on each other. There are a large number of failure scenarios that originate from deployment order, calls to HTTP endpoints, asynchronous messages passed through message brokers like Kafka, indirect dependencies such as through metrics and logs, and compatibility with existing data in databases or in files. A failure to take these scenarios into account or to search for them can result in a massive cost to companies that must go through a repeated and costly process of investigating bugs, cleaning up corrupted data, and repeatedly adding additional changes and going through the entire software development life-cycle .
The presence of difficult technical problems results in a large number of side-effects that have a human element to them. It results in finger-pointing between people in different job roles, especially in engineering, management, and quality assurance. It leads to unpredictable timelines in terms of software completion and conflict with customers, adding business and marketing people to the conflict. It leads to erratic and long working hours that ultimately fall on engineers, who are the only ones with the necessary skills to identify the causes of bugs, actually make software work again, and repair data that is corrupted due to these bugs.
These problems are especially present in companies where management pushes software development to meet unrealistic deadlines, or that views time that is not directly spent on writing code as having no value. Ironically the same lack of understanding ultimately causes management to fail to understand why seemingly “simple” changes can cause so many errors, and proceeds to blame or reprimand the very engineers who are tasked with cleaning up the problems.
Companies that encourage code archeology and permit skilled engineers to conduct assessments before major changes are made, benefit tremendously from faster development times, fewer bugs, and a significantly less stressful work environment which increases employee retention and reduces turnover.