Introduction to Network Security

Table of Contents
Introduction
When building a networked computer system, an inescapable fact that one must contend with, is that a large chunk of the communication between your system and its users will occur over public network infrastructure that you do not own or operate. There is no guarantee that there are not malicious actors who may intercept data, attempt to manipulate it, repeat historic data, or simply try to cause your system to exhaust itself trying to deal with a veritable barrage of bogus requests.
This article attempts to introduce some core network security concepts for those who may be new to the field or lack extensive experience. In our discussion, we will frequently use concrete examples and limit how much depth we dive into for any given area, making it easier to grasp than the normal large piles of in-depth special topics, RFCs, and other technical material.
After reading this article, you should find it much easier to pick up a more technical article on a specific topic, and go in, knowing where it fits into the bigger picture, and how you want to use it.
Network Security Threats
When it comes to securing a web service, there are many ways in which attackers can abuse exposed interfaces in order to attack your service as a whole or to attack specific users. For the sake of this discussion, imagine we have a have a system that has a simple REST API, and we have two endpoints:
- api.myservice.com
HTTP GET /user/{userId}:: Retrieves the data associated with a particular user.HTTP POST /user/{userId}:: Updates the data associated with a particular user.
If no other protection was in place, let’s quickly review some of the ways in which this system could be attacked:
Good Old Fashioned Lying

Lying is such a trivial form of attack that is almost always protected against, thus it doesn’t really have a formal term to describe it. Just look at our silly API:
- api.myservice.com
HTTP GET /user/{userId}:: Retrieves the data associated with a particular user.HTTP POST /user/{userId}:: Updates the data associated with a particular user.
Well, what happens if any random person says, “Hey, I’m user 1234, give me all the data!”, whether they are actually user 1234 or not?
It is so trivially easy to lie, that no reasonably secure system accepts what a user provides as face value without further authentication. What is authentication? In a nutshell, it’s basically verifying that someone is who they claim to be, and that they’re not just lying.
There are many ways of authenticating a person, but they all basically follow a similar form:
- Step 1: Collect information that is unique to a person at the time they create an account.
- Step 2: When a person wants to access information in an account, have them provide proof that they are the same person who created the account in the first place.
- Step 3: Compare the provided proof to the information that was provided at the time of account creation.
Common methods of performing authentication include:
- Having a person sign their name during account creation, and then have a person produce the same signature in the same handwriting, in order to access that account.
- Having a person take a photograph during account creation, and then having the person show their face and compare it to the one on file for the account, in order to access that account.
- Giving a person a unique physical object, like a key, when they create the account, and require them to bring that key to access the contents of their account.
- Ask the person creating the account to create a unique secret passphrase associated with the account, and to access their account, they must repeat this passphrase.
Each of these methods of authentication offer some protection, but are not fully secure. For example, someone can forge a signature, wear a disguise, steal a key, or overhear your password. More secure systems actually require a person accessing an account to provide multiple authentication factors, e.g. a physical object (like your cellphone) as well as a password.
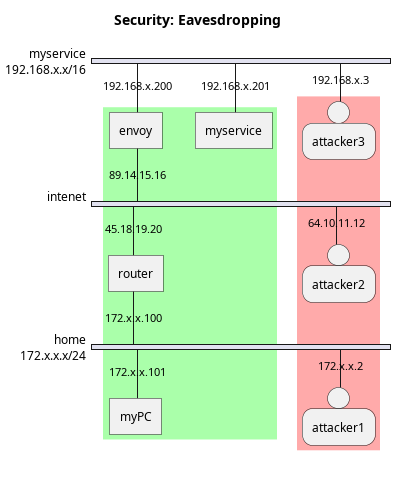
Eavesdropping Attack
A central element that one must consider when communicating over the Internet is that much of the common infrastructure consists is shared. Abusing this common infrastructure is what an eavesdropping attack is all about. That common infrastructure can be attacked at multiple levels using different techniques. For example:
- Physical Layer: The attacker can actually connect to physical wires and cables to read data. This is often called wiretapping.

- Link Layer: A common link-layer protocol is Ethernet, a protocol that was designed around making use of a shared medium, such as a Cat 5 cable. Conflicts are avoided through time-division multiplexing, however, nothing stops an attacker who is connected via a network hub from simply listening to network packets that others are transmitting. Thankfully, the usage of network switches has dramatically lowered the threat of this kind of attack.

- Network Layer: When network packets are routed through the Internet, where to forward a packet to is decided by routing tables updated and maintained by network routers. These routing tables and updated using RIP Protocol, where routers effectively advertise what other networks they are able to reach, and how many network hops they are away from that network. Routers, upon hearing about a route, add it to their own routing tables, and record their distance as being 1 greater than the distance that the router who advertised this route indicated. However, any computer may act as a router, in fact, you can simply connect one in your own home and it will integrate itself into the global network. Attackers can do this as well, and they can purposely advertise a low number of network hops to reach a certain distance, purposely trying to trick computers into routing through them, and then recording those packets as they pass through.

The attackers can be closer to your home network, in the route between your computer and the service you are trying to reach, or even in the network of the service itself.
Man in the Middle Attack
A man-in-the-middle attack takes a slightly different approach from an eavesdropping attack. At its heart, the attack consists of tricking users into believing that they are acting with the service they desired, and in fact, allowing them to interact with that service, but in reality, the attacker is receiving and recording requests, getting the response from the real service, and sending that response back to the user.
To better illustrate this concept, imagine that your favorite pizza place is called Website’s Pizza, and they offer a delivery service of you call one of their restaurants. You’ve recently moved to a new area, and you don’t know the phone number of your local Website’s Pizza. Luckily, you see a flyer attached to a lamppost that says you can reach Website’s Pizza by dialing (121) 1234-5678.

Hungry for pizza, you call the number, give them your credit card information, and shortly thereafter, a pizza arrives at your doorstep. A day later, you notice that your bank balance is lower than it should be, and you discover that you were charged for 10 pizzas instead of 1!

What happened? Well, your local neighborhood troublemaker, Sneaky Sam, is the one who put that poster on the lamppost. As it turns out, Website’s Pizza is real, but their phone number isn’t (123) 1234-5678, it’s actually (123) 4444-5555! When you thought you were talking to Website’s Pizza, you were in fact talking to Sneaky Sam! Sneaky Sam took your credit card information, and then called Website’s Pizza to order your pizza, just so that you would not suspect any problems. But now that he has your credit card information, he used it to to order 9 more pizzas for himself as well!

Sneaky Sam put out a fake poster, they advertised a false number, and thereby took your phone call and was able to capture all the information that you provided.
The same trick can be done on computer networks as well. When you browse to a website using a URL like http://myservice.com, the first step of fulfilling this request is for your browser to call a DNS Server to determine what IP address is associated with the name myservice.com. If the Internet-visible server for myservice.com is at IP 61.62.63.64, it is possible that an attacker can create create a fake DNS Server that advertises that the name myservice.com actually belongs to a fake server at IP 30.31.32.33. The fake server at 30.31.32.33 can simply receive requests, forward them to the real server at IP 61.62.63.64, record the information, and then return the response back to the original caller. In essence, Sneaky Sam put on his technology hat, and used the DNS Server as his digital lamppost, advertising a fake IP instead of a fake phone number.
There are many ways in which an attacker can insert a machine they control in between you and the service you are trying to reach including:
- Advertising a fake DNS record, tricking your computer to using their IP address.
- Abuse IP routing to attempt to route your requests to a server they own.
- Creating a DNS name that is similar to the desired one, but slightly different, e.g.
my-service.comormyservice.co.uk, and then simply forwarding requests and data to the realmyservice.com, while also recording the information they desire.
Securing Network Systems
Using Authentication – Thwarting Lying
We’ve discussed the general pattern of having authentication, having a user specify some unique piece of information that only they can produce, and then asking for that information when they try to access their account.
Let’s revisit our interface again, and see how we should perceive it in light of this new knowledge:
- api.myservice.com
HTTP GET /user/{userId}:: Retrieves the data associated with a particular user.HTTP POST /user/{userId}:: Updates the data associated with a particular user.
This interface doesn’t do any authentication at all, it simply asks the user to provide a user ID as part of the request. This allows not only a stranger to guess or steal a user ID and gain access, but it can also allow a legitimate user to access the data of another user entirely!

But if you don’t get the user ID from the URL path, URL query string, or an HTTP header, then where are you supposed to get it from? The answer is that you should NEVER get the user ID from any place that the user has the ability to manipulate themselves, otherwise you are creating a hole in your security that can be attacked.
There are several strategies for tackling this problem, which generally fall into three broad categories:
- Authenticate Every Request: Require the authentication information, like a password, with every single request. Due to the sheer inconvenience of this approach, it is rarely used in any system where users make a series of interactions as part of a user session.

- User a Server-Side Session: In this approach, after a user logs in, they are given a “session id”, which they can attach to subsequent requests as a cookie, header, query parameter, or anything else. The server uses this session ID to look up data, such as the user ID, from a data cache like Redis. How is this any different than simply putting the user ID in the request? Session IDs are chosen from a space that is so large that it is virtually impossible to guess. E.g. using a UUID-like session ID, such as “37c84e2a-ccfa-4e9c-bb74-674e345299f6”, which has 32 characters with 62 values per character, would require 10248 years of guessing if you could do 1000 guesses per second.

- Use Signed Session Information: We will briefly discuss digital signatures later in this article, but the important property they have, is that any modification that a user makes to them can be detected and rejected. Thus, after the user logs in, they receive session information wrapped up in a digitally signed object, like a JWT, which then contains information like the user ID, their customer tier, etc. The user can see and attempt to manipulate this information, but any attempt will cause the digital signature to fail and the request to be rejected.

Securing Passwords – Authenticating Responsibly
After reading the above background information, one might be tempted to go off and implement your own system to simply store people’s passwords in a database, and then when they try to access your system, compare what they enter to what was stored in the database.
This would be a terrible mistake, and companies that have made similar mistakes have been the subject of major leaks. Don’t repeat these silly mistakes and take a moment to think more about sensitive data that you store in your system. By keeping passwords in a database, that database becomes the target of attackers. Even if your company has flawless security protecting it from any and all external attackers, what if the attacker is a disgruntled employee who has access to this database?
Let us look at a more sophisticated system, such as Keycloak, and see what their policy is on storing passwords:
Keycloak does not store passwords in raw text but as hashed text, using the PBKDF2 hashing algorithm. Keycloak performs 27,500 hashing iterations, the number of iterations recommended by the security community. This number of hashing iterations can adversely affect performance as PBKDF2 hashing uses a significant amount of CPU resources.
https://www.keycloak.org/docs/latest/server_admin/#password-database-compromised
Hashing functions are interesting in the sense that there are multiple inputs that can produce the same output, and very small changes in the input result in large changes in the output. This makes it extremely hard to figure out what a password was, even if you have the output of a hash function.

A super simple algorithm that demonstrates this concept would be the following algorithm that produces a very weak 16-bit hash using 8-bit characters.
// Produces a 16-bit hash from a password.
short hash(const char[] password) {
// The initial hash value is 0.
short hash = 0;
int i = 0;
// Consume 2 characters of the password at a time.
while (i < password.length) {
// Use 1 character for 8 bits of our new block.
short block = password[i];
i++;
if (i < password.length) {
// Use the 2nd character for the other 8 bits of the block.
block = cast(short)((block << 8) | password[i]);
i++;
}
// Combine a block with our hash by shifting our hash by 1 bit,
// and then using XOR to combine with the new block.
hash = cast(short)((hash << 1) ^ block);
}
return hash;
}Code language: D (d)Using this simple algorithm, the password “abcd” produces a hash of 1010000110100000, or -24160. Many passwords can produce the same hash value, including: “uiKr”, “liyr”, and “ZMdnH”.
When a user first sets up their account, the password they enter is passed through a hashing function and only that value is stored in the database, so instead of storing a password of “abcd”, only the value -24160 is stored. When the user tries to access their account, they enter the same password, it is passed through the same hashing function, and only if it also produces a value of -24160 will that password be accepted.
This means that, even if the database that has user credentials is hacked, or the data is stolen, only the password hashes are in that database. The passwords are never actually stored on the company system. What doesn’t exist cannot be stolen.
There are many more advanced techniques used to steal user credentials, and a simple hashing algorithm like this would never be used in a production environment, but it has been sufficient to explain the core concept that is in use behind securing passwords.
Encryption – Thwarting Eavesdropping Attacks
So far so good, we’ve discussed how to securely store information that only the account creator knew when they created their account, that we can later use to authenticate them, and prevent someone else from just lying and trying to access another user’s data.
What do we do about eavesdropping attacks? Can’t someone who is listening on the network simply pick up information that was sent, which would naturally include any password that was used to authenticate a user? Why yes indeed, they could, and using a password to authenticate without also making your communication hidden from eavesdroppers would be almost completely useless.

At its heart, encryption involves converting input information into a form that is not readable by anyone unless they know specific secret information needed to interpret that information. When the secret information needed to encrypt a message also works to decrypt that message, the encryption is said to be “symmetric”. When the information needed to encrypt a message is different from the information needed to decrypt that message, the encryption is said to be “asymmetric”.

Generally, symmetric encryption tends to be faster and require less computational resources to perform, but the longer it is used, the less secure it becomes. The reason is that everyone involved in using the symmetric encryption is a possible target of an eavesdropper, and if any one channel of communication is leaked, then they can decrypt all the messages, regardless of whether it is even the same user, or even if it was an old message.
For this reason, asymmetric encryption is still very useful in many applications, despite the fact that it takes more computational resources to use it. For example, to allow anyone to send secret information that only you can read, the encryption and decryption keys can be used as follows. One encryption key is handed out publicly, the key to encrypt information can be given to all people, so that anyone can encrypt a message to send to you. And the decryption key is kept secret, held only by you, and shared with nobody else.
This situation can also be reversed. The public key can allow anyone to decrypt a message that you write, and the private key can be used to encrypt the message. The most common use case for such an arrangement is to implement what is called a “digital signature”. Like your own personal unique handwriting, only you can write it, and anyone else who has another sample of your handwriting can validate that the signatures match and that you are indeed the same person. Digital signatures are frequently used to prevent “man-in-the-middle” attacks.
HTTPS – Authentication + Encryption
Applying encryption to HTTP communication in order to prevent eavesdropping and man-in-the-middle attacks is exactly what HTTPS was created for.
There are a few core concepts to understand in order to know exactly what HTTPS is:
- X.509 Certificate: This is the standard format used for a digital certificate, defined by RFC 5280. Digital certificates contain information needed to share a public encryption key, and they have been digitally signed by a Certificate Authority.
- Certificate Authorities: A certificate authority is an organization that stores, signs, and issues digital certificates. They exist in a form of a hierarchy, with each certificate authority able to sign certificates for other organizations to authenticate them. This means that, eventually, there is a top of that hierarchy, a set of root certificate authorities that you must accept on faith. Web Browser organizations actually include a list of validated root Certificate Authorities that have been individually vetted as trustworthy. For example, Mozilla Firefox has 148 Certificate Authority records that are automatically trusted.
- Transport Level Security (TLS): This is a TCP network protocol described by RFC 5246 that attempts to establish a secure line of communication over an insecure medium. Starting from a known list of trusted Certificate Authorities, the client validates that the certificate presented by the server is both valid and corresponds with the DNS name that was used to reach the server. The client also uses the public key to encrypt information, and the server can only make sense of this information if it really does posses the private key, which is needed to decrypt it. Once the client is able to authenticate the server, both server and client agree on a symmetric encryption key, which is used for the remainder of the session (which makes it computationally more efficient).
- HTTP Secure (HTTPS): HTTPS uses TLS to initiate a connection and establish a secure communication channel which is based on valid X.509 Certificates. But the actual protocol that is sent, in encrypted form, over the communication channel is HTTP.
If you want to exchange any kind of secret information over your web service, not just credentials like a user’s password, but any information that belongs to a user and should remain private, including the very URLs that they choose to browse, then you should always configure your web service to use HTTPS as quickly as possible!
HTTPS is critical for protecting again both man-in-the-middle attacks and eavesdropping attacks.
Conclusions
The number of ways in which a system can be attacked is truly immense, and any article that attempts to capture them all can, at best, only give an incomplete picture. Here we have tried to cover some of the most common vectors of attack, including users providing false information (lying), trying to intercept information that was meant to be private (eavesdropping), and inserting themselves into the middle of a user session by forwarding communication to a real service, but at the same time, getting full access to the data being exchanged (man-in-the-middle).
To address these kinds of attacks, we’ve introduced and explained the basic concepts around authentication, using secret information to prove that someone claiming to make a request on behalf of a user is, in fact, that user. We also introduced the concept of encryption, which makes a message indecipherable to others who are not direct parties of that communication. There were two types of encryption introduced. There is symmetric encryption, which is fast and efficient, but is as risk of being leaked if the key used to encrypt that information is obtained by another. There is also asymmetric encryption, which uses different keys to encrypt and decrypt information. There are two common uses for asymmetric encryption, using a public encryption key, allowing anyone to send communication that only a certain recipient can read, and digital signatures, which allow a certain party to write information, and others in the public can validate if the information was truly written by that party or not.
Finally, we introduce the underlying technologies behind HTTPS communication. An X.509 certificate is a standard format for advertising public keys, and they are digitally signed by a hierarchy of certificate authorities (CA). Most browsers contain a list of root-level certificate authorities where are known to be trust worthy. An HTTPS session begins by using TLS protocol, which is used to authenticate servers based on their certificates, validated by certificate authorities. Once this happens, an encrypted channel of communication is established, which hides the message contents as well as the URL paths being accessed.
In subsequent articles, we’ll dive into the practical aspects of setting up and enforcing network security protections.
2 Responses
Hiya! Quick question that’s completely off topic. Do you know how to make your site mobile friendly? My blog looks weird when viewing from my iphone 4. I’m trying to find a theme or plugin that might be able to fix this issue. If you have any suggestions, please share. Thank you!
It actually takes a considerable amount of work using plain HTML and CSS to make a site mobile-friendly. My recommendation would be to use a site-builder like Word-Press to to start from an existing theme in a static site generation tool like Jeckyll or Hugo.